日前,智源研究院在其主办的大模型评测线上发布会上,针对国内以及全球范围内共计140多个开源和商业闭源的语言及多模态大模型进行了深度评估,涵盖了各类能力测试。
在具体测试过程中,从主观和客观两个角度出发,全面衡量了语言模型的七大核心能力,包括简单理解、知识运用、推理能力、数学能力、代码能力、任务解决以及安全与价值观等方面。而对于多模态模型,重点关注了其多模态理解和生成能力。
在中文语境下,尽管国内头部语言模型的整体表现已经接近世界领先水平,但仍存在能力发展不平衡的问题。例如,在多模态理解图文问答任务上,开源和闭源模型的表现不分伯仲,其中本土模型表现尤为出色。此外,国产多模态模型在中文语境下的文生图能力与国际一流水平之间的差距相对较小。然而,在多模态模型的文生视频能力方面,通过比较各家公布的演示视频长度和质量,发现Sora具有显著优势,而在其他开放评测的文生视频模型中,国产模型PixVerse的表现同样优秀。
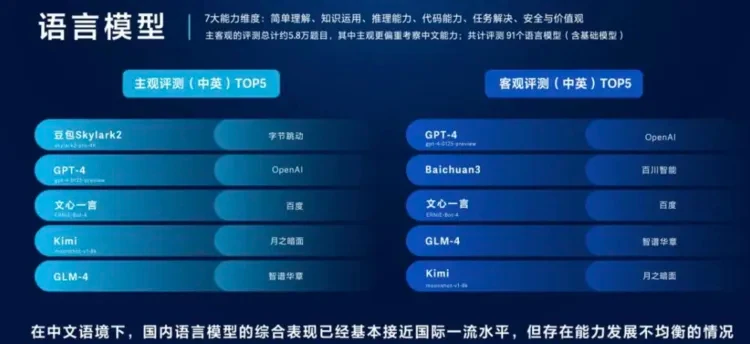
值得注意的是,由于安全与价值观的一致性是模型产业落地的重要前提,但海外模型与国内模型在此维度上存在差异,因此语言模型的主客观评测总成绩并不包含这一单项得分。根据语言模型主观评测结果,在中文语境下,字节跳动旗下的豆包Skylark2和OpenAI的GPT-4分列第一和第二名,充分体现出国产大模型对中国用户需求的深入洞察。在语言模型客观评测中,OpenAI的GPT-4和百川智能的Baichuan3则分别位列第一和第二。同时,百度的文心一言4.0、智谱华章的GLM-4以及月之暗面的Kimi也成功跻身语言模型主客观评测的前五名。
多模态理解模型客观评测结果显示,图文问答方面,阿里巴巴通义 Qwen-vl-max 与上海人工智能实验室 InternVL-Chat-V1.5 领先于 OpenAI GPT-4,LLaVA-Next-Yi-34B 。

多模态生成模型文生图评测结果显示,OpenAI DALL-E3 位列第一,智谱华章 CogView3、Meta-Imagine 分居第二、第三。多模态生成模型文生视频评测结果显示,OpenAI Sora、Runway、爱诗科技 PixVerse、Pika、腾讯 VideoCrafter-V2 位列前五。

图注:Mdjourney 基本无法理解中文提示词,因此排名靠后;仅使用其官方公布的 prompts 和视频片段与其他模型生成的视频进行对比评测,评测结果存在一定的偏差。
首次联合权威教育机构进行大模型 K12 学科测试
智源研究院联合与海淀区教师进修学校对齐学生测验方式,考察大模型与人类学生的学科水平差异,其中,答案不唯一的主观题,由海淀教师亲自评卷。
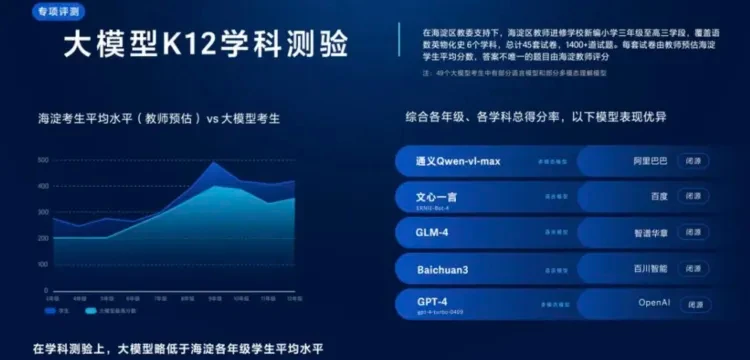
根据智源评测,尽管大模型在综合学科能力上已达到海淀学生的平均水平,但文科强而理工弱,且缺乏对图表的准确理解,故其成长潜力巨大。
海淀教师进修学校校长姚守梅分析大模型K12学科测试数据后表示,模型在人文学科如语文、历史考试中的表现不如预期,难以把握文字背后的深层含义和家国情怀;在处理历史地理综合题时,也未能有效识别学科特性。然而,面对较为复杂的英语问题,模型却显示出优越性。此外,在解答理科问题时,模型有时会采用超纲的解决策略,甚至在遇到难题时产生“误解”。
构建文生视频模型主观评价体系
中国传媒大学智能媒体计算实验室主任史萍教授认为,相较于文本,视频的主观评价难度极大。自动化指标无法全面反映模型生成质量,更无法量化视频的真实性、图文一致性等因素。因此,有必要构建一套系统化的文生视频模型主观评价体系。
此评价体系由智源研究院与中国传媒大学结合各自在大模型评测和视频质量评价方面的深厚学术积累与实践经验共同制定,从图文一致性、真实性、视频质量、美学质量四个维度进行评分,为AIGC视频生成技术的应用与发展提供指导。